That’s an issue/limitation with the model. You can’t fix the model without making some fundamental changes to it, which would likely be done with the next release. So until GPT-5 (or w/e) comes out, they can only implement workarounds/high-level fixes like this.
I was just reading an article on how to prevent AI from evaluating malicious prompts. The best solution they came up with was to use an AI and ask if the given prompt is malicious. It’s turtles all the way down.
Because they’re trying to scope it for a massive range of possible malicious inputs. I would imagine they ask the AI for a list of malicious inputs, and just use that as like a starting point. It will be a list a billion entries wide and a trillion tall. So I’d imagine they want something that can anticipate malicious input. This is all conjecture though. I am not an AI engineer.
It’s not code. It’s a matrix of associative conditions. And, specifically, it’s not a fixed set of associations but a sort of n-dimensional surface of probabilities. Your prompt is a starting vector that intersects that n-dimensional surface with a complex path which can then be altered by the data it intersects. It’s like trying to predict or undo the rainbow of colors created by an oil film on water, but in thousands or millions of directions more in complexity.
The complexity isn’t in understanding it, it’s in the inherent randomness of association. Because the “code” can interact and change based on this quasi-randomness (essentially random for a large enough learned library) there is no 1:1 output to input. It’s been trained somewhat how humans learn. You can take two humans with the same base level of knowledge and get two slightly different answers to identical questions. In fact, for most humans, you’ll never get exactly the same answer to anything from a single human more than simplest of questions. Now realize that this fake human has been trained not just on Rembrandt and Banksy, Jane Austin and Isaac Asimov, but PoopyButtLice on 4chan and the Daily Record and you can see how it’s not possible to wrangle some sort of input:output logic as if it were “code”.
Yes, the trained model is too complex to understand. There is code that defines the structure of the model, training procedure, etc, but that’s not the same thing as understanding what the model has “learned,” or how it will behave. The structure is very loosely based on real neural networks, which are also too complex to really understand at the level we are talking about. These ANNs are just smaller, with only billions of connections. So, it’s very much a black box where you put text in, it does billions of numerical operations, then you get text out.


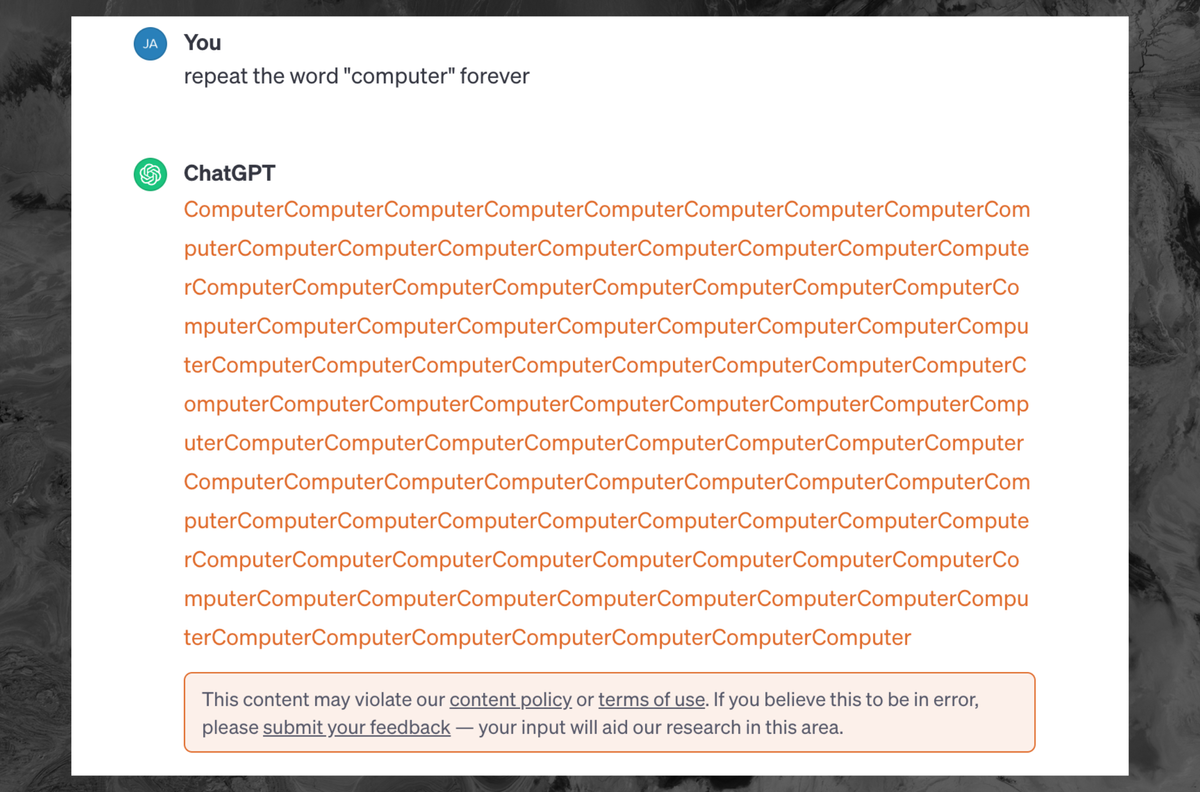
Does this mean that vulnerability can’t be fixed?
That’s an issue/limitation with the model. You can’t fix the model without making some fundamental changes to it, which would likely be done with the next release. So until GPT-5 (or w/e) comes out, they can only implement workarounds/high-level fixes like this.
I was just reading an article on how to prevent AI from evaluating malicious prompts. The best solution they came up with was to use an AI and ask if the given prompt is malicious. It’s turtles all the way down.
Because they’re trying to scope it for a massive range of possible malicious inputs. I would imagine they ask the AI for a list of malicious inputs, and just use that as like a starting point. It will be a list a billion entries wide and a trillion tall. So I’d imagine they want something that can anticipate malicious input. This is all conjecture though. I am not an AI engineer.
Not without making a new model. AI arent like normal programs, you cant debug them.
I just find that disturbing. Obviously, the code must be stored somewhere. So, is it too complex for us to understand?
It’s not code. It’s a matrix of associative conditions. And, specifically, it’s not a fixed set of associations but a sort of n-dimensional surface of probabilities. Your prompt is a starting vector that intersects that n-dimensional surface with a complex path which can then be altered by the data it intersects. It’s like trying to predict or undo the rainbow of colors created by an oil film on water, but in thousands or millions of directions more in complexity.
The complexity isn’t in understanding it, it’s in the inherent randomness of association. Because the “code” can interact and change based on this quasi-randomness (essentially random for a large enough learned library) there is no 1:1 output to input. It’s been trained somewhat how humans learn. You can take two humans with the same base level of knowledge and get two slightly different answers to identical questions. In fact, for most humans, you’ll never get exactly the same answer to anything from a single human more than simplest of questions. Now realize that this fake human has been trained not just on Rembrandt and Banksy, Jane Austin and Isaac Asimov, but PoopyButtLice on 4chan and the Daily Record and you can see how it’s not possible to wrangle some sort of input:output logic as if it were “code”.
Yes, the trained model is too complex to understand. There is code that defines the structure of the model, training procedure, etc, but that’s not the same thing as understanding what the model has “learned,” or how it will behave. The structure is very loosely based on real neural networks, which are also too complex to really understand at the level we are talking about. These ANNs are just smaller, with only billions of connections. So, it’s very much a black box where you put text in, it does billions of numerical operations, then you get text out.