
- cross-posted to:
- technology@lemmy.world
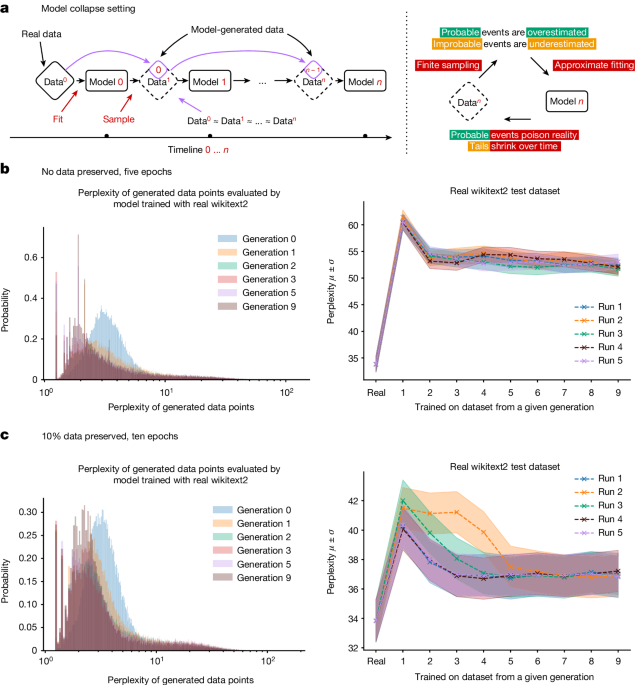
- cross-posted to:
- technology@lemmy.world
You must log in or # to comment.
Yep. It leads to a positive feedback loop. They just continue to self-reinforce whatever came out before.
And with increasing amounts of the internet being polluted with AI text output…
… AI inbreeding.
hapsburgGPT
deleted by creator
In the USA, they call it the AlaLlama model.
GPTargaryen
What about the Grrr! model after that astoundingly XD So Random! thing from Invader Zim?
He’s an android or robot, right?
deleted by creator
That seems so obviously predictable.
To be fair this doesn’t sound much different than your average human using the internet.
2024, Reverse Turing Test Challenge:
Can an LLM AI differentiate between human input and LLM AI input?
You have to pretty much intentionally give it enough synthetic data to wreck it. OpenAI and Anthropic train their models on generated data to improve them. As long as there’s supervision during training, which there always will be, this isn’t really a problem.
https://openai.com/index/prover-verifier-games-improve-legibility/
Well… Its built on statistics and statistical inference will return to the mean eventually. If all it ever gets to train on is closer and closer to the mean, there will be nothing left to work with. It will all be the average…
Holy shit are you telling me…
Garbage In…
= Garbage Out?
No, that can’t be it, throw billions and billions of dollars at this instead of, I don’t know, housing the homeless.
You realize that those “billions of dollars” have actually resulted in a solution to this? “Model collapse” has been known about for a long time and further research figured out how to avoid it. Modern LLMs actually turn out better when they’re trained on well-crafted and well-curated synthetic data.
Honestly, everyone seems to assume that machine learning researchers are simpletons who’ve never used a photocopier before.
This has been obvious for a while to those of us using GitHub Copilot for programming. Start a function, and then just keep hitting tab to let it autotype based on what it already wrote. It quickly devolves into strange and random bullshit. You gotta babysit it.
very unlikely to stem from model collapse. why would they use a worse model? it’s probably because they neutered it or gave it less resources.
It learns from your own code as you type so it can offer more relevant suggestions unlike the web-based LLMs. So you can make it feed back on itself.
Where did you learn to write such shitty code?
I learned it from watching you!
Same thing with Stable Diffusion if you’ve ever used a generated image as an input and repeated the same prompt. You basically get a deep-fried copy.
img2img is not “training” the model. Completely different process.
Oh yeah, you’re right. It’s both degradation in some way, but through entirely different causes.
No shit. People have known about the perils of feeding simulator output back in as input for eons. The variance drops off so you end up with zero new insights and a gradual worsening due to entropy.
Garbage in garbage out
It’s an old expression, but it still checks out
deleted by creator
No.
Eventually an AI will be developed that can learn with much less data. In the end we don’t need to read the entire internet to get through our education. But, that’s not going to be LLM. No matter how much you tweak LLM models, it won’t get there. It’s like trying to tune a coal fired steam powered car until you can compete in a formula 1 race.
Yeah, it’s entirely plausible that LLMs are a small part of the answer as basically the language center of the brain, but the brain is a hell of a lot more complex than that. The language center isn’t your whole brain, and is only loosely connected to actual decision making. It confabulates a lot.
OpenAI stumbled on something that worked and ran with it, and people started proclaiming it to be the answer to everything. The same happened with Deep Learning and every AI invention so far. It’s all just another stepping stone on the way.
It’s already happening. A quote from Andrej Karpathy :
Turns out that LLMs learn a lot better and faster from educational content as well. This is partly because the average Common Crawl article (internet pages) is not of very high value and distracts the training, packing in too much irrelevant information. The average webpage on the internet is so random and terrible it’s not even clear how prior LLMs learn anything at all.
You don’t say, Sherlock
So do humans if I’m being honest, look at the RNC.
Can’t wait
No shit.
( Horseshack voice: )
Oh! Oh! Oh! Mr Kotter!
YOU MEAN FILTER-BUBBLES DO THE SAME THING TO BOTH HUMANS AND AIs??
How Very Incredibly Surprising™, Oh, My!
/s
_ /\ _









